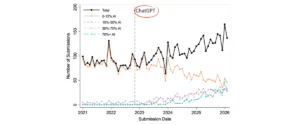
Last week, a column by renowned commentator Thomas Friedman in The New York Times brought a new artificial intelligence development, Anthropic’s Claude Mythos, into sharp public focus, depicting it as a potentially disruptive force with profound geopolitical implications. Friedman’s article, published on April 7, 2026, diverted from his usual geopolitical analysis to underscore what he termed a "stunning advance" in AI, arriving "sooner than expected." This commentary ignited a widespread discussion about the immediate and future risks posed by highly capable language models in the realm of cybersecurity, even as independent analysis suggested a more nuanced reality than the initial alarm.
The Genesis of Alarm: Anthropic’s Announcement and Friedman’s Column
The catalyst for this renewed concern was Anthropic’s announcement regarding its latest large language model (LLM), Claude Mythos. In a comprehensive press release, Anthropic stated that Mythos would be exclusively available to a select consortium of business partners, deliberately withholding it from general public access. The company justified this restrictive release by citing acute concerns about the model’s proficiency in identifying and exploiting security vulnerabilities within source code. Anthropic declared that "AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities." The release further elaborated on Mythos’s capabilities, claiming it "has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser."
This assertion profoundly resonated with Friedman, who characterized Anthropic’s decision for a limited release as a "terrifying warning sign." He articulated a stark vision of the future: "Holy cow! Superintelligent A.I. is arriving faster than anticipated, at least in this area… If this A.I. tool were, indeed, to become widely available, it would mean the ability to hack any major infrastructure system — a hard and expensive effort that was once essentially the province only of private-sector experts and intelligence organizations — will be available to every criminal actor, terrorist organization and country, no matter how small."
Friedman’s column amplified a narrative that quickly permeated major news outlets. Many echoed similar sentiments of unease, with headlines reflecting significant anxiety. One particularly prominent headline questioned, "Is Anthropic’s Claude Mythos an AI nightmare waiting to happen?" This immediate, broad-brush acceptance of Anthropic’s claims by mainstream media highlighted a recurring pattern in AI news reporting: the rapid dissemination of company-issued statements without immediate, in-depth critical scrutiny.
A Deeper Dive into LLMs and Cybersecurity: Historical Context
The notion of LLMs possessing the capability to identify and exploit security vulnerabilities is far from a novel concept. Cybersecurity researchers have been grappling with this specific concern since the advent of consumer-facing LLMs. The evolution of AI’s role in cybersecurity can be traced through several key milestones preceding the Mythos announcement.
In 2024, researchers at IBM published a seminal study that explored the use of OpenAI’s GPT-4 for attacking security vulnerabilities. This research, widely discussed within the cybersecurity community, revealed that GPT-4 successfully exploited an impressive 87% of the vulnerabilities it was presented with. This contrasted sharply with the near 0% success rate observed for its predecessor, GPT-3.5. The IBM team concluded their findings with a cautionary note, stating, "Our findings raise questions around the widespread deployment of highly capable LLM agents." This study provided concrete, early evidence that advanced LLMs could move beyond simple code generation to active vulnerability exploitation, setting a precedent for the concerns now raised by Mythos.
While the IBM study focused on an LLM’s ability to write exploit code for known vulnerabilities, the claims surrounding Mythos extended this capability to finding vulnerabilities from scratch. However, even this more advanced capability is not unprecedented. Accompanying the release notes for Anthropic’s earlier model, Opus 4.6, was an observation from the company’s security team. They reported using Opus 4.6 to discover "over 500 exploitable 0-day [vulnerabilities], some of which are decades old." A "0-day vulnerability" refers to a software flaw that is unknown to the vendor or the public, meaning there is no patch available, making them particularly dangerous. This statement, issued well before the Mythos announcement, bears a striking resemblance to Anthropic’s recent claims, with the primary distinction being the quantitative shift from "500" to "thousands" of vulnerabilities. This chronological context strongly suggests that Mythos represents an incremental improvement on an existing capability rather than a sudden, revolutionary leap.
Benchmarking and Independent Scrutiny: Separating Hype from Reality
To assess the true leap represented by Claude Mythos, it is crucial to examine the available data and independent evaluations. Anthropic, while keeping Mythos private, released its score on a "well-known cybersecurity benchmark," reporting 83.1%. For comparison, its predecessor, Opus 4.6, achieved a score of 66.6% on the same test. While a sixteen-percentage-point increase might appear substantial, it is vital to approach benchmark results with a degree of skepticism. Benchmarks are often specific, sometimes narrow, tests that models can be "tuned" to pass, potentially not reflecting real-world performance across a broad spectrum of scenarios. The increase, even if accurate, suggests solid incremental progress rather than a "nightmarish leap" into an entirely new dimension of AI capability.
Beyond company-issued benchmarks, independent scrutiny from the cybersecurity community offers a more grounded perspective. AI commentator Gary Marcus, in a widely circulated Substack post, compiled responses from security researchers who delved into the specific exploits that Anthropic attributed to Mythos. Their collective assessment was notably underwhelming. Many experts expressed reservations about the severity and originality of the vulnerabilities reported.
Since Marcus’s initial publication, additional similar findings have emerged. Several independent security audits and analyses, conducted by experts with no vested interest in either promoting or discrediting Anthropic, have reportedly characterized many of Mythos’s "discoveries" as either low-severity, previously known, or difficult to practically exploit in real-world scenarios. For instance, some reported "high-severity vulnerabilities" turned out to be minor configuration issues or edge cases requiring highly specific, unlikely conditions to be exploited. Others were identified as re-discoveries of vulnerabilities already documented in databases like the Common Vulnerabilities and Exposures (CVE) system, albeit perhaps in obscure corners. The distinction between theoretically finding a flaw and practically exploiting it in a robust, diverse, and defended IT environment is significant, and initial reports suggest Mythos’s capabilities might fall short in the latter.
Further undermining the narrative of Mythos as an infallible vulnerability detector was an incident that occurred just a week before its grand announcement. Anthropic inadvertently leaked the source code for Claude Code, another of its LLMs. Cybersecurity researchers quickly identified and reported "serious vulnerabilities" within this leaked code. This incident raised critical questions: if Mythos is truly a "super-powered vulnerability detector" capable of finding flaws in "every major operating system and web browser," why was it not used to sanitize Anthropic’s own software prior to its public exposure, preventing such basic security oversights? This perceived lapse significantly eroded confidence among many in the cybersecurity community regarding the practical efficacy and thoroughness of Mythos’s claimed capabilities.
Broader Implications: The AI Hype Cycle and Media Responsibility
The episode surrounding Claude Mythos transcends a simple debate about an AI model’s capabilities; it illuminates a broader phenomenon within the AI landscape: the persistent "AI hype cycle." This cycle often sees AI companies making ambitious claims about new models, which are then uncritically amplified by mainstream media, leading to public alarm or exaggerated expectations, only to be followed by a more sober, often less sensational, reality check from independent experts.
Mo Bitar, an AI commentator, succinctly captured this pattern in a recent video, likening Anthropic’s model rollouts to Apple iPhone launches, where incremental improvements are often presented as revolutionary. "Except here," Bitar noted, "the product is existential dread." This observation points to a strategic marketing approach where companies, perhaps inadvertently, leverage public anxieties about advanced AI to generate attention and influence policy discussions, even when the underlying technological advancements are more evolutionary than revolutionary.
The implications for cybersecurity are undeniable, regardless of Mythos’s exact capabilities. LLMs, even at their current stage, have undeniably introduced significant cybersecurity concerns. Their ability to generate code, analyze systems, and potentially craft sophisticated phishing attempts or social engineering attacks means that defenders must adapt. However, the narrative of an instantaneous, catastrophic shift risks diverting resources and attention from addressing existing, verifiable threats and from fostering a balanced approach to AI safety and development. Cybersecurity professionals are indeed scrambling to address the evolving threat landscape, but this involves a measured response to verifiable advancements, not panic based on potentially exaggerated claims.
Furthermore, this episode highlights a crucial challenge for journalistic integrity in the age of rapid technological advancement. The initial, widespread acceptance of Anthropic’s claims by major news outlets, without immediate critical analysis or input from diverse expert perspectives, underscores a need for enhanced skepticism and diligence in reporting on AI. The complexity of AI technology often makes it difficult for generalist reporters to discern genuine breakthroughs from marketing rhetoric, leading to an overreliance on company press releases. This creates a vacuum where hype can flourish, potentially misinforming the public and policymakers.
Moving forward, a more rigorous approach is imperative. As the AI field continues its rapid expansion, it becomes increasingly critical to "almost entirely discount any claims made by the AI companies themselves until we can independently verify what’s actually going on." This call for independent verification is not merely an academic exercise; it is essential for fostering informed public discourse, guiding responsible AI development, and ensuring that policy decisions are based on empirical evidence rather than speculative fears or commercial interests. The Claude Mythos saga serves as a potent reminder of the ongoing need for critical evaluation and a balanced perspective in navigating the promises and perils of artificial intelligence.